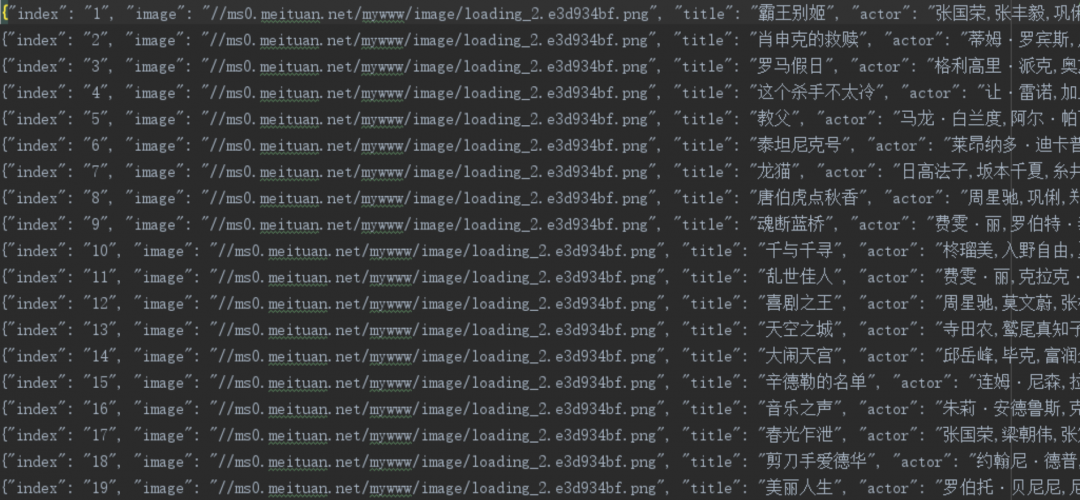
上課啦!Python爬蟲系列課程之爬蟲基礎介紹
爬蟲是什么?
爬蟲:一段自動抓取互聯網信息的程序,從互聯網上抓取對于我們有價值的信息。
如果我們把互聯網比作一張大的蜘蛛網,數據便是存放于蜘蛛網的各個節點,而爬蟲就是一只小蜘蛛,沿著網絡抓取自己的獵物(數據)。爬蟲指的是:向網站發起請求,獲取資源后分析并提取有用數據的程序。
從技術層面來說就是通過程序模擬瀏覽器請求站點的行為,把站點返回的HTML代碼/JSON數據/二進制數據(圖片、視頻) 爬到本地,進而提取自己需要的數據,并將數據存放起來加以利用。
爬蟲的基本流程
用戶獲取網絡數據的方式:
方式1:瀏覽器提交請求--->下載網頁代碼--->解析成頁面
方式2:模擬瀏覽器發送請求(獲取網頁代碼)->提取有用的數據->存放于數據庫或文件中
爬蟲要做的就是方式2,通過程序模擬瀏覽器,程序代替人工。流程如下:
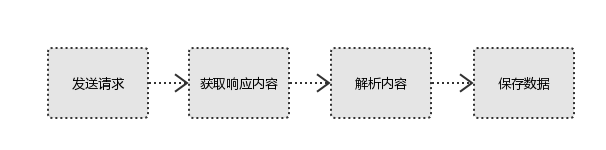
1、發起請求
使用http庫向目標站點發起請求,即發送一個Request。
Request包含:請求頭、請求體等。
Request模塊缺陷:不能執行JS 和CSS 代碼。
2、獲取響應內容
如果服務器能正常響應,則會得到一個Response。
Response包含:html,json,圖片,視頻等。
3、解析內容
解析html數據:正則表達式(RE模塊),第三方解析庫等。
解析json數據:json模塊。
解析二進制數據:寫入文件。
4、保存數據
數據庫(MySQL,Mongdb、Redis等)
本地文件
為什么選擇Python爬蟲
Python爬蟲是用Python編程語言實現的網絡爬蟲,主要用于網絡數據的抓取和處理。相比于其他語言,Python是一門非常適合開發網絡爬蟲的編程語言,大量內置包,可以輕松實現網絡爬蟲功能。
Python提供了較為完整的訪問網頁文檔的API.
對比其他語言用Python開發速度快,代碼簡潔干凈。
Python請求與響應
通過Python的爬蟲包發送WEB請求,獲取響應信息。
Python自帶了urllib和urllib2爬蟲包。urllib和urllib2都是接受URL請求的用于網絡請求的相關模塊,彼此各有利弊,urllib和urllib2通常一起使用。
而requests與scrapy是目前比較常用的Python數據采集包。也是大數據省賽、國賽數據采集步驟的指定考核范圍(近幾年的大數據競賽數據采集步驟考核內容都是requests或scrapy)。
Python解析內容
解析內容就是將需求數據從響應的整體頁面信息中提取出來的過程。
爬蟲的數據采集可以幫助我們獲取網站的頁面內容,但頁面內容會比較多并不是所有的頁面信息都是我們需要的。頁面的指定字段才是有價值的,才是我們想要得到的內容。對于獲取的數據需要進行解析提取需求數據,正則表達式與xpath(lxml包)是目前比較常見的解析工具。
正則表達式是Python自帶的包,Xpath需要安裝lxml包。
正則表達式描述了一種字符串匹配的模式(pattern),可以用來檢查一個字符串是否含有某種子串、將匹配的子串替換或者從某個字符串中取出符合某個條件的子串等。
例子:
import re
# 正則規則
nameReg = "title=\"(.+?)\""
# 整體信息
msg = ""
# 正則處理
msglist = re.findall(nameReg, msg, re.S | re.M)
# 提取內容
print(msglist)
結果:
['百度搜索']
XPath 是一門在 XML 文檔中查找信息的語言。XPath使用路徑表達式來選取 XML 文檔中的節點或者節點集。這些路徑表達式和我們在常規的電腦文件系統中看到的表達式非常相似。
例子:
from lxml import html
xml_doc = """
first item
second item
third item
"""
# 轉換格式,用于xpath獲取指定內容
dom_tree = html.etree.HTML(xml_doc)
# xpath規則
msg = dom_tree.xpath("//li/a/text()")
# 循環獲取的節點內容
for text in msg:
print(text)
結果:
['百度搜索']
first item
second item
third item
Python保存數據
將解析內容持久化,保存到數據庫或本地文件。常見操作有MySQL保存與csv文件保存。
保存到MySQL:通過pymysql操作數據庫,使用insert into語句插入數據。
保存文件:file.write(“輸出內容”)。
爬蟲過程示例
此處只做演示,后續課程會講解詳細過程。
1、查看要訪問的WEB頁面。
2、requests發送請求并獲取響應內容。
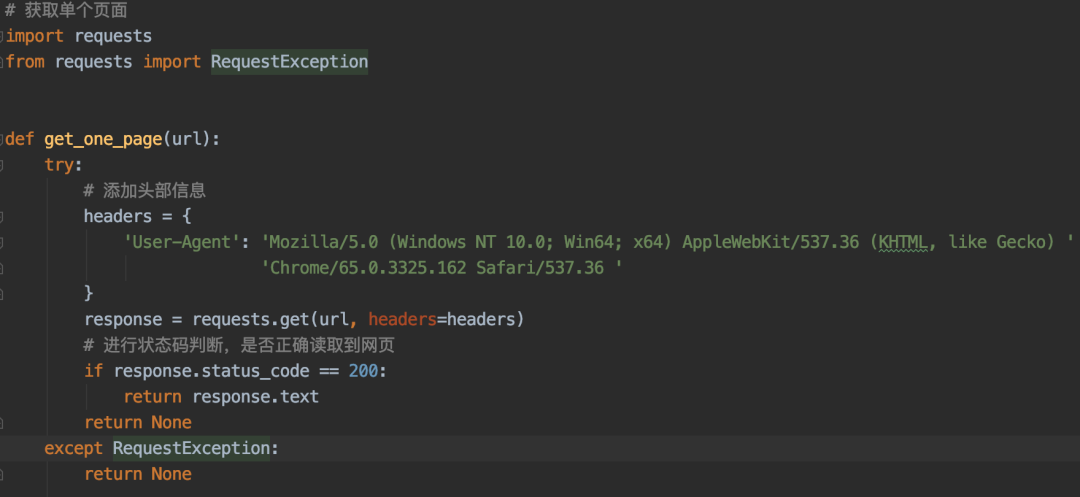
3、解析頁面內容,提取需求字段。
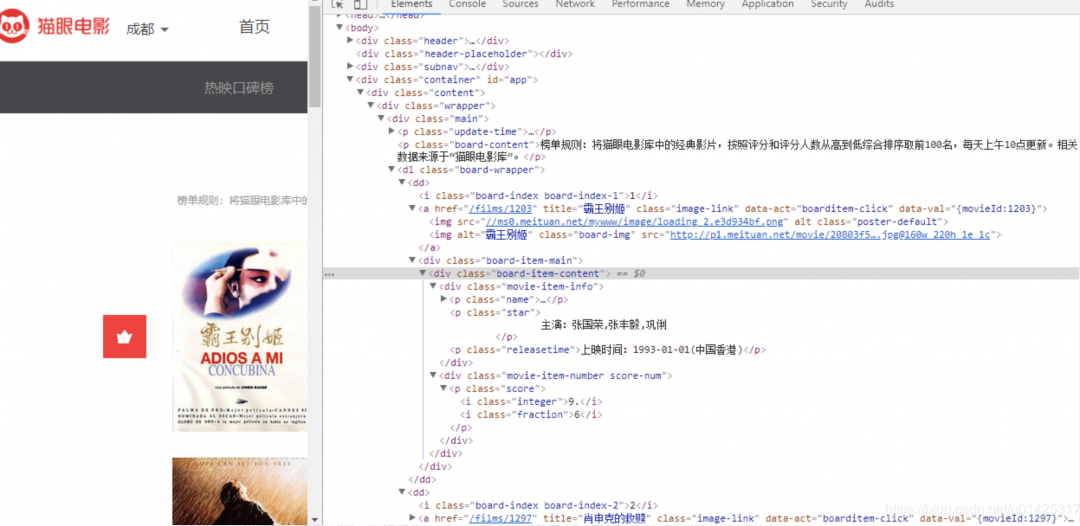
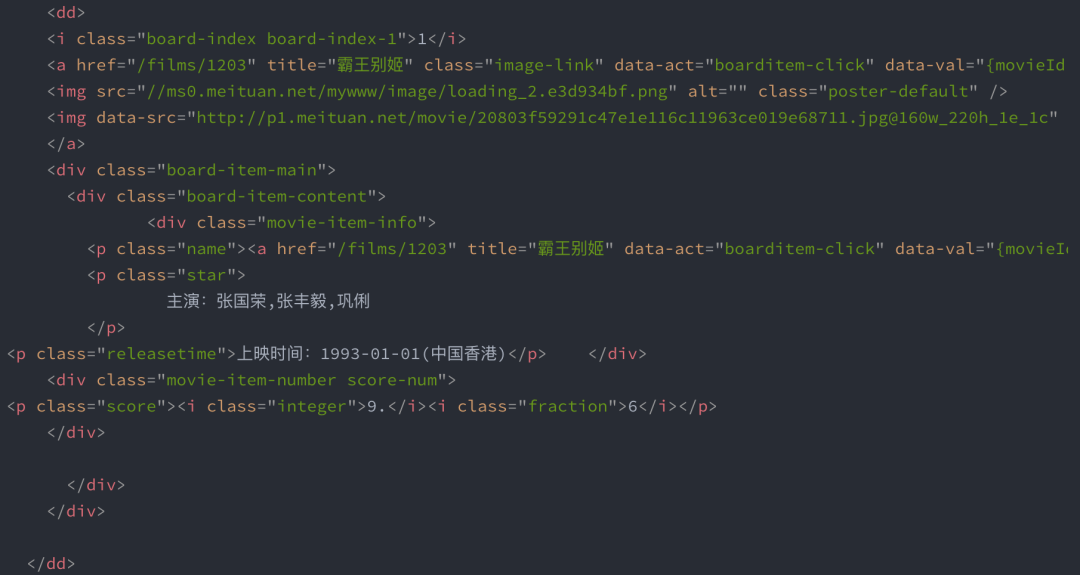
4、保存內容